|
|
Architecture of an analytical data
environment
Chip Hartney (The Datamology Company)
First written: October 26, 2022
Last updated: January 18, 2024
Contents
Data
warehouse (single data store)
Data
mesh (multiple data stores)
Data
fabric (multiple data stores)
Data
mall (multiple data stores)
Abstract
An analytical data environment will be comprised of many analytical data stores (each with many data assets). In general, an individual analytical data store can take various forms including:
· Virtual server
· Replica of an operational data store
· ODS
· Data warehouse
· Data lake
· Data lakehouse
· Data mart
· etc
The question arises as to how to architect the overall environment. This is a complex question and depends on many organization-specific realities. There is no single answer for all orgs and I make no attempt to provide such an answer. Instead, I simply present the standard industry approaches and my take on each.
Data warehouse (single data store)
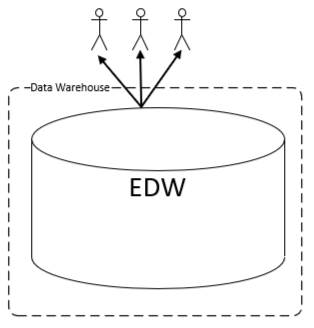
This is a centralized architecture in which a single data store supports all analytical needs. Given that the data store serves all needs, it is (by definition) an enterprise data warehouse (EDW). This is the original approach that was championed by pioneers like Bill Inmon and Ralph Kimball in the 1990s. Serious concerns have been raised over the ensuing years as to the advisability of this approach. Most data warehousing projects that pursued this approach eventually were abandoned, usually after extraordinary expenditures of money and time. In the 21st century, the champions themselves altered their recommendations to address some (but not all) of the problems that were encountered.
Another common concern is single-vendor lock-in. Once the solution is realized, you are dependent on a single technology solution. You are at risk of absorbing increasing costs over time if the vendor’s fee increase. And the cost of switching vendors is a lever that encourages you to stay with the original vendor even if those increases are large.
This approach is incompatible with the use of supplemental data stores such as Avatar DW.
I do not believe that even a modernized version of this approach is a best practice because it locks the organization into the use of a single solution at a time when the number of useful and viable solutions has exploded … and will continue to do so!
· Whereas we were long content with analyzing structured data, we now look to incorporate semi-structured and unstructured data. Those typically require the use different technologies.
· Also, there are new storage constructs that have proven useful in more recent decades. While relational databases have been the data workhorses of most organizations for decades, there is be a place for object-oriented, graph, document, NoSQL, and NewSQL databases.
· Similarly, recent decades of seen the introduction of new data storage and access technologies to address the exploding velocity and volume of data. These again have proven useful, of course, and have typically been adopted in addition to other solutions, not instead of them.
· The case can also still be made for the very first approach to decision support, that of offloading the analytic load from operational systems by simply creating a copy of the operational data store.
· And we see continual evolution of platforms on which data can be stored. On-prem and off-prem. Mainframe, server, cloud, etc.
· Proprietary off-the-shelf data warehouse solutions are available. While one might try to leverage such as the sole data store for an organization, it is generally impossible to customize such to address all needs of the organization. So these have a place, but typically as an additional DW in the analytical data environment, not as the sole analytical data store.
· Many operational applications, especially the larger ones, offer data warehousing extensions that can be turned on simply. They offer great immediate functionality but, like their proprietary siblings, are usually impossible to customize to address all needs of the organization. So, again, they typically wind up being an additional data store in the overall environment.
Putting it simply, I do not think it realistic for any organization to assume their analytical data environment will be comprised of a single data store in the future even if they think that one would suffice now. I believe an org will always want the ability to extend its analytical data environment with new data stores without being required to configure and manage them in a manner consistent with the EDW standard. This is especially true for out-of-the-box, third-party analytical solutions that an org may find beneficial in the long run (such as a “data warehouse” extension to one of their operational systems).
There is still some acceptance of this approach in the industry. However, I observe that this approach is usually only considered in a greenfield environment where no prior investment has been made in other data stores which would, necessarily, need to be refactored and replaced to realize this architecture.
Data mesh (multiple data stores)
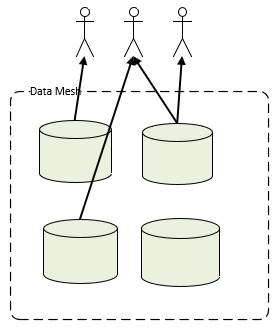
This is an architecture in which distributed domain-centric data stores are utilized and each would support self-service in a common manner (giving the overall environment a user-friendly consistency). Technically, a data mesh is an architecture with:
· Domain-oriented decentralization of data ownership and architecture
· Domain-oriented data served as a product
· Self-serve data infrastructure as a platform to enable autonomous, domain-oriented data teams
· Federated governance to enable ecosystems, interoperability, and observability
This is a difficult option for me to fully review and comment on because I lack experience with this architecture. It was first introduced by Zhamak Dehghani, a principal technology consultant at ThoughtWorks, in 2019 and is not yet common in the industry. Further, I am unaware of successful implementations, at least in smaller organizations.
I understand this architecture to be best-suited for domain-oriented data teams because it generally lacks an enterprise wide, integrated view of the business. I.e., no EDW! (Though one might think of the entire data mesh as the EDW.) Given that this approach misses the stated goal of an integrated, enterprise-wide solution, I am inclined to rule out this approach from the get-go. But, again, to be fair, I may be wrong about that! However, it strikes me that it is left to the data consumer to integrate data from the different domains on-the-fly, which can be a tall order. I expect this shortcoming to be ameliorated somewhat by strong governance that leads to interoperability. But strong governance is usually a reach for a small organization.
Data fabric (multiple data stores)
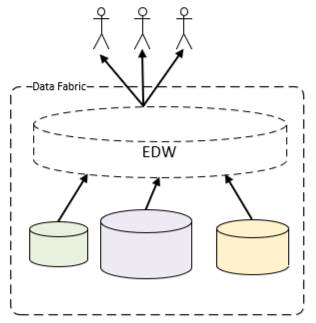
This is an architecture in which various data stores are placed behind a virtual abstraction (the data fabric) of the data environment such that the data consumer interacts with the fabric instead of the individual data stores. The fabric acts as a virtual EDW, interpreting each request and obtaining the appropriate data from the pertinent data stores as needed.
An analytical data fabric is also known as a logical data warehouse or a virtual data warehouse.
This architecture is highly extensible and, once implemented, allows the organization to add new data stores, move or change existing ones, or remove old ones without impacting the data consumers or their applications. The value of these benefits cannot be overstated. This is huge. But, as with all benefits, there are associated costs.
The fabric is a software product, such as Denodo, and (not surprisingly) is expensive. After all, such a product must support a myriad of possible data stores.
A common concern about such an architecture is that it leads to worse overall performance. After all, a query submitted directly to a particular data store (such as SQL Server) will necessarily take longer if it is first directed to another technology before being passed on to the intended target for processing. And there is an increase in processing costs that accompanies the involvement of the additional technology.
This architecture also requires a refactoring of all analytical solutions (which is typically done up-front to get the greatest benefit of the conversion). Whereas they previously accessed a specific data store, they now must access the fabric, instead. This conversion can be a cumbersome and expensive endeavor.
Another common concern is single-vendor lock-in. Just as in the single data warehouse architecture, once this solution is realized, you are dependent on a single technology solution. You are at risk of absorbing increasing costs over time if the vendor’s fee increase. And the cost of switching vendors is a lever that encourages you to stay with the original vendor even if those increases are large.
Though a fan of this architecture in larger organizations, I am not aware of small organizations that have adopted this approach, likely for some of the reasons cited above.
Data mall (multiple data stores)
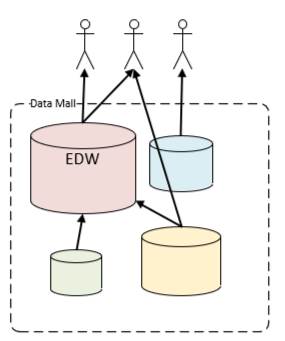
This is an architecture in which various data stores operate mostly independently. Light governance is required to ensure the data stores do not overlap or duplicate each other. To address the need for an enterprise-wide view of the business, one of the data stores is designated as the EDW. Integrated, enterprise-wide solutions are implemented in this EDW whereas the other data stores are dedicated to other purposes. The EDW can utilize data in those other data stores through virtual means such as a relational view.
This architecture is well-suited for small organizations that cannot afford the costs (staff, budget, time) of the more robust multi-store architectures noted above and brownfield environments that are de facto data malls to begin with. In the latter cases, it is a simple matter to adopt this architecture formally because there is no refactoring needed.
This, in fact, is the current analytical data architecture in most any organization that has not previously pursued a robust data warehousing strategy.
This architecture also lends itself to incremental evolution (whereas the others require substantial up-front refactoring) and offers the opportunity to build it out at a pace that matches the organization’s needs and abilities.
But there is still substantial work to be done before the environment is fully mature:
· If an existing data store is to become the EDW, a significant effort is likely required to convert it to that new purpose. Further effort will be required to build it out over time.
· If a new data store is to become the EDW, a significant amount of effort is required to build it to completion because you are starting from scratch. Further, additional effort will be required to remove duplication from other data stores as it is built.
Until the environment is fully mature, many of the initial problems that led to the consideration of an EDW to start with will continue to exist. If you choose to build a new EDW from scratch, you will likely introduce even more redundancy early on. That can be alleviated by establishing a policy of removing duplication as the new EDW capabilities are established. But that increases the development time and costs of those early solutions. Putting it another way, you must choose between living with redundant data stores or spending the time to refactor existing solutions and eliminate that redundancy as the new solution is built. Note that the redundancy spoken of here is only partial. If the entire solution already existed, there would be no need to build a new solution.
Substantial effort will also be needed to educate your analysts. Education (in the form of training and documentation) is needed for every architecture, but this architecture requires more because of the partial redundancies and the confusion that arise from such.