|
|
Sharing data between systems
Author: Chip Hartney (The Datamology Company)
First written: October 27, 2022
Last updated: October 28, 2022
Contents
Abstract
In this article, I describe the sharing of data between systems (internal or external) and the ramifications of doing so.
I pay special attention to how this applies to analytical data. Analytical data is different than operational data (which is fully maintained by the operational application that it serves). Analytical data is built from other data stores and it is, in turn, shared with other users and systems. I.e., there is a lot of “sharing” going on … meaning data flows in to and out of the analytical data environment. It’s important to understand data sharing.
The general case
Let’s look first at the general case in which one party (or system) provides the data to another.
Analogy
Consider the following data sharing situation in the physical world. Two people (Debbie and Taleb) store information (various files) in their respective offices (in file cabinets). Debbie needs some files that are in Taleb’s office. They can address the need in a one of the following ways:
1. Debbie establishes a self-serve kiosk outside her office (backed by a robotic backend system) from which anyone can store files. Taleb goes to his office, gets the pertinent papers out of his file cabinets, and goes to Debbie’s kiosk where he identifies and provides the files. The robotic system stores the files in the cabinets (unknown to Taleb) in Debbie’s office. Note that this solution requires only Taleb’s involvement and is only appropriate when Taleb identifies the need.
2. Taleb goes to his office and gets the pertinent papers out of his file cabinets. He then goes to Debbie’s office and places the papers in her file cabinets. Note that this solution requires only Taleb’s involvement and is only appropriate when Taleb identifies the need. Further, it requires Taleb to have access to Debbie’s office and to have complete and accurate knowledge of Debbie’s filing system.
3. Taleb goes to his office and gets the pertinent papers out of his file cabinets. He may use a kiosk/robotics system to facilitate that, if he chooses. Debbie doesn’t care. He then leaves the files in an agreed upon handoff area from where Debbie can retrieve them at any time. Debbie then goes to her office and places the files in the pertinent cabinets there. She may use a kiosk/robotics system to facilitate that, if she chooses. Taleb doesn’t care. Note that this solution requires both Debbie’s and Taleb’s involvement.
4. Debbie goes to Taleb’s office and gets the pertinent papers out of his file cabinets. She then returns to her office and places the papers in the pertinent cabinets there. Note that this solution requires only Debbie’s involvement and is only appropriate when Debbie identifies the need. Further, it requires Debbie to have access to Taleb’s office and to have complete and accurate knowledge of Taleb’s filing system.
5. Taleb establishes a self-serve kiosk outside his office (backed by a robotic backend system) from which anyone can obtain files. Debbie goes to Taleb’s kiosk and identifies the desired files. The robotic system retrieves the files from cabinets in Taleb’s office which are unknown to Debbie and delivers those files to the kiosk (and, therefore, to Debbie). Debbie takes the files back to her office and places them in the pertinent cabinets in her office. Note that this solution requires only Debbie’s involvement and is only appropriate when Debbie identifies the need.
Note: It is possible there is a self-serve kiosk on both ends. However, the kiosks cannot talk to each other. A human must be involved to decide which files are to be shared. And, if a human is involved, they do not need to use their own self-serve kiosk because they are masters of their own filing system.
Sharing approaches
Diagram
Here is the digital equivalent of the physical analogy above:
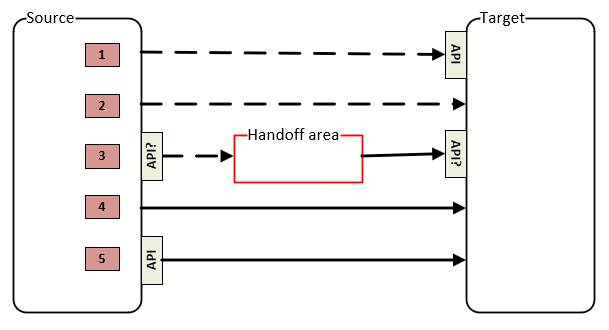
Notes:
1. APIs are self-service interfaces.
a. Note: A given data store may not provide such an API.
b. In the case of the asynchronous data flow (with a handoff area), it does not matter whether an API is available. The owner of the ETL may or may not use it as they wish (it is theirs after all).
2. Dashed arrows represent “push” data flows (that the Source manages).
3. Solid arrows represent “pull” data flows (that the Target manages).
The approaches (identified by red boxes) are:
1. Self-service push
2. Direct sharing - push
3. Coordinated sharing
4. Direct sharing - pull
5. Self-service pull
Each is described a bit further below.
Self-service push
The Source determines the need and uses the API provided by the Target.
Direct sharing - push
The Source determines the need and writes data directly into the Target.
Coordinated sharing
Either party can determine the need but the parties must work in a coordinated manner. The Source provides the data. The Target consumes the data. This can be done synchronously or asynchronously.
Direct sharing - pull
The Target determines the need and reads data directly from the Source.
Self-service pull
The Target determines the need and uses the API provided by the Source.
Direct sharing
As seen above, direct data sharing can be supported in either of the following ways:
· Direct push … in which the Source writes data directly to the Target’s backend data store.
· Direct pull … in which the Target reads the data directly from the Source’s backend data store.
But is this wise?
In each case, one party must have direct access to the backend data store for the other party. More importantly, the party must have complete and accurate knowledge of other’s data storage system and its organization. The effect is that of tightly coupling the two systems together and any change to the either system may break the solution!
DAMA’s DMBOK addresses this issue:
Where possible, loose coupling
is a preferred interface design, where data is passed between systems without
waiting for a response and one system may be unavailable without causing the
other to be unavailable.
Where the systems are loosely
coupled, replacement of systems in the application inventory can theoretically
be performed without rewriting the systems with which they interact.
Per industry best practices, a system should not be tightly coupled with any other system and, even better, the integration should be asynchronous (which is not possible in a direct sharing approach).
Direct sharing should never be used. Here are some reasons why:
· The org that is reaching into the other’s system likely has no expertise in that system and is likely to do a poor job.
· The org whose system is being reached into loses control over the activity taking place in that system.
· The org whose system is being reached into must expose their data to external entities, loosening information security and making it difficult to manage.
· The ETL process (written by one org) impacts performance of the other org’s system.
· The ETL process (being maintained by an external org) is not managed by the team that owns the system being accessed and may not even be known to that team. It is very difficult to manage, let alone accommodate, those processes.
· It is very difficult to coordinate changes to the ETL process with changes to the pertinent system (because the two are managed by different orgs).
· Every ETL would be a unique and distinct interface, with little commonality. The number of such interfaces can easily explode.
Therefore, the architecture described in this document uses only self-service and coordinated sharing
Self-service sharing
As seen above, self-service data sharing can be supported in either of the following ways:
· Self-service push … in which the Source writes data to the Target via a self-service API.
· Self-service pull … in which the Target reads the data from the Source via a self-service API.
When such a capability is available and appropriate for the use case, this is the preferred approach to data sharing because it is fully under the control of the interested party and incurs no burden on the other party.
Note the use of “appropriate” in the above. It is not appropriate to use a self-service push (where the Source develops the solution) in use cases where the Target is the owner of the use case. And vice versa.
Coordinated sharing
As noted above, when an appropriate self-service interface is available to facilitate data sharing, it should be utilized. But, when self-service is not an option, coordinated sharing must be utilized meaning that the sharing of data required by one system requires assistance from the other system.
Contracts
The key to effective data sharing, whether self-service sharing or coordinated sharing, is a contract between the Source and the Target as to the way the data is shared including such aspects as:
· The way the data is exchanged.
· The timing of the exchange.
· The form of the data.
· The content of the data.
· The key to the data.
· The availability of the data.
· How changes to the contract are to be made.
In self-service sharing, the contract is the documentation describing the self-service interface, itself, as provided by the owner of that interface. The other party is free to use the interface, per that contract, without otherwise involving the owner of the interface (other than to become an authorized user of the interface).
In coordinated sharing, the contract is an agreement between the provider and recipient which describes the specific dataset that is to be shared and the way it is shared.
It is strongly recommended that all such contracts be formal and recorded so that each party is aware of all dependencies and can operate with confidence that the other parties will not interfere with their operations.
The format and content of that dataset must be mutually agreed to (preferably per a formal contract). It is a simple matter (and best practice) to utilize a standard canonical format to accelerate such agreements and simplify the handoffs.
Handoff area
As seen above, coordinated sharing requires the use of a handoff area, the place where the data provider (source) transfers the data to the data recipient (target). The use of a handoff decouples the two systems and allows for asynchronous processing (a desirable feature).
The handoff area must be available to both the data provider (with WRITE privileges) and the data recipient (with READ privileges). That area is then, by definition, distinct from the data stores owned by the individual parties. Furthermore, the handoff area, needs to retain the data only temporarily, just long enough to complete the exchange.
It is acknowledged that the use of a handoff area in data sharing comes at a cost:
· Added latency (it takes longer for the data to make its way from the provider to the recipient).
· Added cost (it uses storage which must be paid for).
· Additional orchestration (between the ETL that loads data in the handoff area and the ETL that extract the data from the handoff area).
The benefits, however, outweigh such costs:
· Decouples the systems.
· Reduces overall amount of coding (and, therefore, cost of implementation).
· Eliminates need for public APIs on either system.
· Supports restartability of data interface processes.
· Provides a physical audit trail for the data.
· Supports clearer data lineage.
· Allows the provisioned dataset to be utilized by multiple consuming processes.
· Provides a single, easy-to-manage point of interface control.
· Provides the basis of a more robust data interface (pub/sub, service bus, data exchange, etc).
The analytical case
Now let’s look at data sharing in the context of an analytical data environment which:
· Ingests data from providers.
· Egests data to recipients.
Remember: Direct sharing is an anti-pattern and, therefore, should not be supported.
Diagram
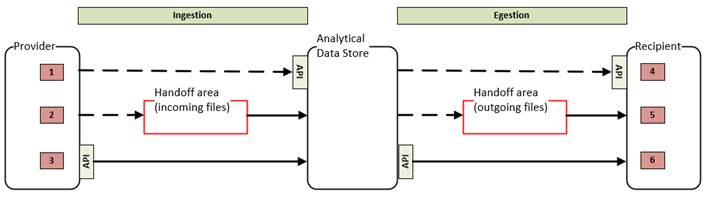
Notes:
1. APIs are self-service interfaces.
a. Note: A given data store may not provide such an API.
2. Dashed arrows represent “push” data flows (that the Source manages).
3. Solid arrows represent “pull” data flows (that the Target manages).
4. Re ingestion:
a. The Provider is the Source and has WRITE access to the incoming section of the Handoff area.
b. The Analytical Data Store is the Target and has READ access to the incoming section of the Handoff area.
5. Re egestion:
a. The Analytical Data Store is the Source and has WRITE access to the outgoing section of the Handoff area.
b. The Recipient is the Target and has READ access to the outgoing section of the Handoff area.
The approaches (identified by red boxes) are:
1. Ingestion: Self-service push
2. Ingestion: Coordinated sharing
3. Ingestion: Self-service pull
4. Egestion: Self-service push
5. Egestion: Coordinated sharing
6. Egestion: Self-service pull