|
|
The temporality of data
Chip Hartney (The Datamology Company)
First written: Circa 2016
Last updated: January 19, 2024
Contents
Cynthia
Saracco, Matthias Nicola, Lenisha Gandhi [2012]
C.
J. Date, Hugh Darwen, Nikos Lorentzos [2014]
Tom
Johnston and Randall Weis [2016]
Abstract
Leaving aside the strange implications of quantum mechanics, our world (in fact, the entire universe) is temporal. By that, I mean that there is a meaningful past, present, and future. In analytics, we analyze the past to predict the future. We can only do so in a meaningful manner if we record the temporal aspects of our data. This is especially critical in an analytical environment where we strive to answer questions like:
· How many patients did we serve in November?
· Are our sales increasing?
· What did we report to the government for 2023?
In this article, I strive to provide a fuller understanding of the two critical dimensions of temporality that are pertinent to our data:
· Business time
· System time
Note that data may have many other relationships to time. But the above temporal aspects of our data are those that I mean when I speak of “temporal data".
Expert opinions
It’s not just me!
Joe Celko [undated]
You cannot escape temporal data. You need to get over it.
Richard Snodgrass [2010]
[Bitemporal] features greatly reduce the length and complexity of such modifications in conventional SQL.
Tom Johnston [2011]
If we discover a data error in a version table, we may think we can just apply an update to correct it, but that won’t work. First, it leaves the erroneous version uncorrected. Second, it says that the change begins when the new version is created. Both conditions are wrong.
Cynthia Saracco, Matthias Nicola, Lenisha Gandhi [2012]
Temporal support reduced coding requirements by more than 90% over homegrown implementations.
C. J. Date, Hugh Darwen, Nikos Lorentzos [2014]
Users of data warehouses have begun to find themselves faced with temporal data problems and they’ve begun to feel the need for solutions to those problems.
Barry Devlin [2014]
It certainly is about time that we consider chronology as a key component of data. It’s well-past time to migrate to a bitemporal database.
Tom Johnston [2015]
SCDs must be abandoned. Bitemporal dimensions must be used in their place.
Tom Johnston and Randall Weis [2016]
The accumulation of data in today’s data warehouses does not distinguish between a history of what the data is about and a history of the data itself. Yet this distinction is vital to supporting the real requirements that business users have in mind when they request “historical data”.
Business time
Overview
The first timeline of interest to us ... with regards to temporal data ... is that of ontology (sometimes referred to as state or reality or existence). This timeline is the one to which we refer when we try to understand what has actually occurred in the business’s world. Values in this timeline describe the time at which the things that we are interested in actually existed.
With business time, we are able to answer questions such as:
· When did the ATM transaction occur?
· When was the customer in premier status?
Synonyms for business time include valid time.
Objects
By definition (mine, at least), an object exists across time and, therefore, can change state as time passes. We typically need to track those various states and the period of time during which the object was in any given state. Therefore, to anchor an object to the business timeline, one must record the pertinent period.
Events
By definition (mine, at least), an event occurs at a point in time and, therefore, does not change state. To anchor an event to the business timeline, one must record the pertinent point in time.
Example
Note: This example pertains only to objects (which can change state across time). There is no need for multiple records (with business time periods) when recording data about an event.
In the following example, we track (unitemporally) the state of an object (referred to with a "RefId" of "9999") across business time (BT):
|
RefId |
State |
BT |
|
9999 |
Blue |
3-5 |
|
9999 |
Red |
5- |
Here is a pictorial representation of those same records:
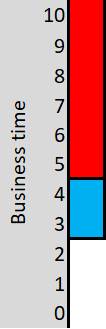
This is to be interpreted as follows:
· The state of the object was "Blue" from time point 3 (inclusive) until time point 5 (exclusive) .
· The state of the object was "Red" from time point 5 (inclusive) until now.
Such a table shows us the state of the object at any point in time. Being unitemporal, we have no record when the records were recorded (and, therefore, when they would have been used in any given report).
System time
Overview
The second history of interest to us ... with regards to temporal data ... is that of epistemology (sometimes referred to as knowledge or truth or belief). This timeline is the one to which we refer when we try to determine what was recorded in our system at any given point in time. Values in this timeline describe the time at which a particular data record was recorded in our system.
Note that, in an ideal world, we would know (i.e., record) everything the instant it actually happened and we would do so perfectly and accurately. But knowledge is (generally) not recorded in real time and the recorded knowledge is sometimes wrong (and, therefore, in need of later correction).
With system time, we are able to answer questions such as:
· What did we know about the event (or object) on a given date?
· Why did the July report show such a high number?
· When did the mistake in our database get corrected?
Synonyms for system time include transaction time.
Example
In the following example, we track (unitemporally) our knowledge about the state of an object (referred to with a "RefId" of "9999") across system time (ST):
|
RefId |
State |
ST |
|
9999 |
Blue |
a-b |
|
9999 |
Red |
b- |
Here is a pictorial representation of those same records:

This is to be interpreted as follows:
· From time point a (inclusive) through time point b (exclusive), our records showed that the state of the object was "Blue".
· From time point b (inclusive) through now, our records showed that the State of the object was "Red".
Such a table shows us what we recorded about the object at any point in time. Being unitemporal, we have no record of when the object was actually in any given state, only when we recorded the information in our data store.
Bitemporal data
Overview
Hopefully, you can see the value of both timelines described above. Both are important! This is especially true of a data warehouse that is expected to be the organization’s system of record for enterprise reporting.
Tracking both business time and system time together results in a bitemporal data asset. Each record in that data asset is to be interpreted as follows:
· The business (ontological) time of the record defines the period of time during which the object was in the recorded state.
· The system (epistemological) time of the record defines the period of time during which the record was utilized.
Because business time and system time are independent of each other, we represent bitemporal data graphically as a two-dimensional plane and, in that representation, each combination of periods is presented as a rectangle in that plane.
Example
Note: This example pertains only to objects (which can change state across time). There is no need for multiple records (with business time periods) when recording data about an event. A unitemporal (system time) solution is sufficient for events.
In the following example, we track (bitemporally) the state of an object (referred to with a "RefId" of "9999") across both business time (BT) and system time (ST):
|
RefId |
State |
BT |
ST |
|
9999 |
Blue |
3- |
a-b |
|
9999 |
Blue |
3-5 |
b- |
|
9999 |
Red |
5- |
b- |
Here is a pictorial representation of those same records:
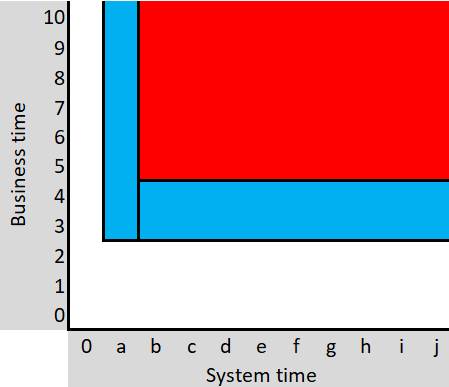
This is to be interpreted as follows:
· From time point a (inclusive) through time point b (exclusive), our records showed that:
o The state of the object was "Blue" from time point 3 (inclusive) until now.
· From time point b (inclusive) through now, our records showed that:
o The state of the object was "Blue" from time point 3 (inclusive) until 5 (exclusive) .
o The state of the object was "Red" from time point 5 (inclusive) until now.
Such a table shows us the state of the object at any point in time as we had recorded it at any point in time.
A real-life example
To understand the difference, consider the following scenario for a single entity (whose Key = 1):
· On 8/15/2022, we learn (from the source system) that the entity came into existence on 6/1/2022 as Red but turned Blue on 8/1/2022.
· On 8/16/2022, we learn (again from the source system, with apologies) that the prior information was a bit wrong. The entity turned Green (not Blue) and that change occurred on 7/1/2022 (not 8/1/2022).
The question is how we faithfully and accurately record that bitemporal history. I.e., how do we record orthogonal timelines in a single dataset.
Traditional solutions
If we track only system time, we are forced to choose which version of the entity (in the business timeline) is to be recorded. I.e., when we record information on 8/15/2022, we must decide whether to record the older Red record or the newer Blue record. Assuming we choose to keep the newest version, the dataset will look like this:
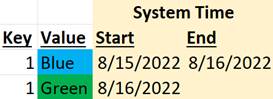
Note: In dimensional modeling terms, this approach is known as a “Type 1 dimension”. A “Type 0 dimension”, by contrast, is one in which we keep the older version.
This is, of course, useless for any entity that changes over time because the most critical aspect of a data warehouse is to expose those changes to support temporal analysis. In this case, we have no record of the entity ever having been Red.
If we track only business time, the dataset will look like this after recording the information on 8/15/2022:

After correcting the data on 8/16/2022, the dataset will look like this:

Note: In dimensional modeling terms, this approach is known as a “Type 2 dimension”.
This is better because it exposes the critical business timeline that is required for temporal analysis.
But it is not auditable. Once the correction is made, we have no record of what the dataset contained prior to the correction. A report produced on 8/15/2022, after the information was recorded, would have indicated (incorrectly) that the entity was Blue. After the correction, of course, the same report would (correctly) return Green. But there would be no way to determine why the original report returned Blue. That information was lost when the records were corrected.
To satisfy such an audit, one would have to depend on backups of the dataset. If we happened to backup the dataset on 8/15/2022, we would have the required evidence to explain why the report returned Blue. But it is unreasonable to expect to have a backup for every situation. The dataset would have to be backed up every time any change is made to it. I.e., you would need to keep every version of the dataset to have full auditability. While that may be acceptable for a single file, it is absurdly impractical for a data warehouse.
The solution is to keep both timelines in the dataset.
The traditional approach (before the invention of temporal databases) was to add one or more system timestamps to the dataset.
First, the industry tried a single system timestamp that recorded when the record was first touched (i.e, INSERTed). In that approach, the dataset will look like this:

This is an improvement in that we can now see that something changed on 8/16/2022. But we cannot distinguish any of the following:
· The original state was not Red but was later corrected.
· The original state was only for the month of June or extended beyond that but was later shortened.
· There were other states prior to 6/1/2022 that were then removed.
· There were later states that were later removed.
· Etc
The industry then tried using multiple system timestamps, one that recorded when the record was first touched (i.e, INSERTed) and a second indicating when the record was last touched (either INSERTed or UPDATEd). In that approach, the dataset will look like this:
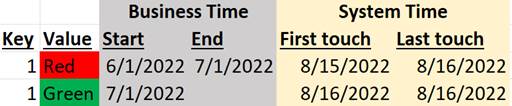
This was, again, an improvement. Now we can distinguish records (such as the Green one) that have not been updated (because the first and last touched system times are the same) from records (such as the Red one) that have been updated. But the approach is still inadequate in most of the ways described previously. And, of course, this approach fails to allow for multiple intermediate touches.
Modern solutions
The fundamental problem with these traditional approaches is that they stive to record when corrections are made to the data but have no ability to record what actually changed. Putting it another way, they attempt to record all of the system timeline within the single business timeline record (which has no other attributes to describe the change).
The key to unlocking this problem is recognizing that, as noted above, the timelines are orthogonal. Here is a 2-dimensional (accurate!) representation of our scenario:
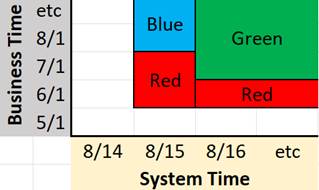
It can be seen that 4 records (2-dimensional boxes) are required to document this scenario, each with its own boundaries in each timeline. Using this approach, the dataset will look like this:
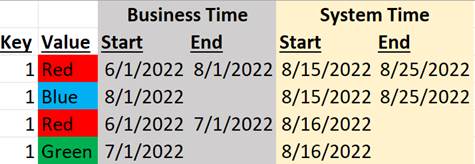
Per the above data records regarding the thing with Key = 1:
· Prior to 8/15/2022, the system knew nothing about it.
· As of 8/15/2022, the system knew the following about it:
o It was Red from 6/1/2022 until 8/1/2022.
o It was Blue as of 8/1/2022.
· As of 8/16/2022, the system knew the following about it:
o It was Red from 6/1/2022 until 7/1/2022.
o It was Green as of 7/1/2022.
Industry experts have long understood this need. But managing (with ETL code) a dataset (relational table) with this kind of structure was extraordinarily difficult. Few attempted to do so. Successes were few and far between and they were very expensive.
After decades of debate the SQL standard was finally changed (circa 2011) to support temporality and database vendors started offering temporal databases.
As a general rule, it has long been recommended that:
· Business time be maintained for any subject that changes over time (such as Client or Employee).
· System time be maintained for all data stores.
With the advent of temporal databases, it is now recommended that:
· Business time is managed by the RDBMS if possible.
· System time is managed by the RDBMS if possible.
Expiration times
Records describing the changes of state of an object over business time must allow the user to know both the effective time and the expiration time of a given state. As a practical manner, the effective time is always recorded directly. But the expiration time need not be (and, in fact, cannot be recorded until it is known). The question arises as to whether the expiration time should be recorded outright (explicitly) or derived from the ensuing record (implicitly). That choice, in turn, dictates whether the ETL is responsible for UPDATEs of existing records.
Consider the following scenario:
· Entity 1 came into existence (red) on 11/5/2022.
· Entity 1 changed to yellow on 11/8/2022.
· Entity 1 went out of existence on 11/12/2022.
That information, with explicit expiration times, would be recorded as follows:
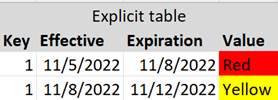
In this approach:
· When the entity came into existence:
o INSERT of first record (with NULL expiration).
· When the entity changed:
o INSERT of second record (with NULL expiration).
o UPDATE of first record (with effective time of second record used as expiration time).
· When the entity went out of existence:
o UPDATE of first record (with death time used as expiration time).
Notice that each type of real-world action requires different database actions (INSERT and UPDATE) and even combinations of actions.
That information, with implicit expiration times, would be recorded as follows:
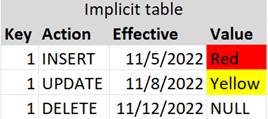
Note that an additional action indicator is needed to understand the terminating record.
In this approach:
· When the entity came into existence:
o INSERT of first record (with INSERT action).
· When the entity changed:
o INSERT of second record (with UPDATE action).
· When the entity went out of existence:
o INSERT of third record (with DELETE action).
Notice that each type of real-world action requires a single database action and it is always an INSERT. The ETL is simpler and faster than the explicit approach. But the user is left to infer the expiration time by reading the following record. (Of course, this can be alleviated by utilizing a view that joins adjacent records together and exposes both times.)
RDBMS support
The SQL standard
The need for management of temporality within RDBMSs was recognized as early as 1990 and frequent requests were made to the SQL standards committees to establish a temporal standard. But the SQL community struggled to reach consensus on how it should be implemented for about 20 years. Finally, temporality was added to the standard as part of SQL:2011 (more formally ISO/IEC 9075:2011), which was officially adopted in December, 2011.
Some RDBMS vendors released product-level support in advance of the new standard and the rest followed. Each vendor has (as is commonly the case) variations in its particular implementation, but it is now safe to say that all major RDBMSs support temporal data … and have for quite some time!
Teradata
Teradata introduced TSQL support in v13.10 (January 2010) and followed with full SQL:2011 support in v15 (January 2016).
DB2
IBM added SQL:2011 support to DB2 in v10 (April 2010).
Oracle
Oracle announced compliance with SQL:2011 in v12c (June 2013).
SQL Server
Microsoft introduced SYSTEM_VERSIONING in v2016 (June 2016).
PostgreSQL
PGXN temporal_tables extension was made available (by arkhipov in GitHub) in ~2016. PostgreSQL doesn’t (last I checked) support these features natively, but this extension approximates them. This requires PostgreSQL 9.2 or higher, as that was the first version with support for a timestamp range data type.
MariaDB
MariaDB, a commercially supported fork of MySQL, implemented system-versioned tables in v10.3 (May 2018).
HANA
SAP introduced temporality in SAP HANA 2.0 SPS03 (May 2018).
Microsoft SQL Server
Overview
Microsoft introduced temporal functionality (system time only) in SQL Server 2016 as system-versioned tables. Azure SQL includes this functionality.
Here is sample SQL Server code that creates a temporal table (with an anonymous history table):
CREATE
TABLE "dbo"."Emp"
(
-- Standard columns
"ID" int NOT NULL PRIMARY KEY,
"Name" varchar(100)
NOT NULL,
"AnnualSalary" decimal (10,2) NOT
NULL,
-- Temporal columns
"ValidFrom" datetime2 GENERATED
ALWAYS AS ROW START,
"ValidTo" datetime2 GENERATED
ALWAYS AS ROW END,
PERIOD FOR SYSTEM_TIME
("ValidFrom", "ValidTo")
)
WITH
(SYSTEM_VERSIONING = ON) -- Temporal instruction
;
After executing the above command, the database contains two tables:

Notes:
· The standard table contains the current version of every record (as always).
· The history table contains old versions of every record.
· SQL Server automatically manages the records, moving them between the tables as necessary.
Example
The table’s data is managed via the same DML statements that would be used for a table that is not system-versioned as in the following examples:
insert
into "dbo"."Emp" ("ID", "Name",
"AnnualSalary") VALUES
(1, 'Chip', 50),
(2, 'Mike', 60)
;
update
"dbo"."Emp" set "AnnualSalary" = 55 where
"ID" = 1;
delete
from "dbo"."Emp" where "ID" = 1;
When interested in only current records, the table is queried via the same DQL statements that would be used for a table that is not system-versioned as in the following examples:
SELECT
* FROM "dbo"."Emp";
Assuming the above DML had been run before this query, the results would be (as expected):
![]()
But we can also use a temporal query to access the old versions of the data as in the following:
SELECT
* FROM "dbo"."Emp"
FOR
SYSTEM_TIME AS OF '2022-05-25 22:09:01.2165662';
Basic query
Further, the SYSTEM_TIME clause can be used in queries against views which, in turn, access system-versioned tables. So, assuming the dbo.EmpView view exposes data from the dbo.Emp table, the following query can be used:
SELECT
* FROM "dbo"."EmpView"
FOR
SYSTEM_TIME AS OF '2022-05-25 22:09:01.2165662';
The SYSTEM_TIME clause is passed to all system-versioned tables underlying any view.
Alternative queries
Use the “BETWEEN” qualifier when you need those rows that overlap the specified period boundaries:
SELECT
* FROM "dbo"."EmpView"
FOR
SYSTEM_TIME BETWEEN '2021-04-01' AND '2021-09-25';
Use the “CONTAINED IN” qualifier when you need those rows that existed within specified period boundaries:
SELECT
* FROM "dbo"."EmpView"
FOR
SYSTEM_TIME CONTAINED IN ('2021-04-01', '2021-09-25');
Use the “ALL” qualifier when you need to query all current and historical data (without restrictions):
SELECT
* FROM "dbo"."EmpView"
FOR
SYSTEM_TIME ALL;