|
|
What is a thing?
Chip Hartney (The Datamology Company)
First written: Circa 2016
Last updated: January 18, 2024
Contents
Types
of things vs things themselves
Abstract
Storing data about things requires someone to establish a model of those things. The data modeling process typically involves all sorts of discussions in which the participants make all sorts of assumptions because most practitioners don’t bother to establish semantics for those discussions. So, you hear things like:
· What things are we modeling?
· What things do we know about those things?
Just what things are we talking about?
Surprisingly, this question has been maddeningly hard to answer ... having been asked for millennia by many really smart people starting with Democritus, Plato, and Aristotle and later examined by more smart people like Porphyry and Brentano. As in all universes of discourse, we are only able to talk intelligently about these things if we settle on a common lexicon.
In this article, I propose an ontology that I have found extremely useful in such modeling discussions, the theoretical basis for that ontology, and the usage of that ontology in modeling data stores.
Types of things vs things themselves
To get this discussion going, it is necessary to understand the difference between things, themselves, and the "type" of which each is an instance. Various fields of study have tackled this distinction and used, of course, various terminology. Here's a quick summary of some of those approaches:
|
Field |
Type |
Thing |
|
Philosophy |
Universal |
Particular |
|
Language |
Predicate |
Subject |
|
Math
(set theory) |
Collection |
Member |
|
Object-oriented
programming |
Class |
Object |
|
Data
modeling |
Entity |
Instance |
In each case, the goal is to distinguish those "things" which exist individually (such as a specific leaf that I pluck from the tree in my friend's yard) from the categories into which they can be grouped (such as "Leaf").
Each approach further allows for sub-types (such as simple and compound leaves). And those sub-types can be further broken down (such as palmately compound and pinnately compound leaves).
Given that we are data people, I use the data modeling terminology ... that of entities and instances ... to distinguish types of things from the things, themselves. And I will try (because it is convenient) to consistently follow the object-oriented programming practice of capitalizing the entity (i.e., "Leaf"), but not the instance, itself (i.e., "leaf").
Ontology
With those foundational terms as our building blocks, I now define an ontology by which we can understand entities and instances from a data perspective. By "ontology", I mean an "explicit specification of a shared conceptualization" (per Tim Gruber, 1993).
This ontology is based on Aristotelean ontology, the branch of metaphysics dealing with the nature of being, because that undergirds set theory which, in turn, undergirds relational theory which is, finally, the basis on which relational databases are built.
In our approach, everything (sorry!) is a Thing. The question we really care about is what type of Thing any given thing (instance of Thing) is. To answer that, I use the following top-level hierarchical ontology (a data-centric and simplified variation of Aristotle's philosophic ontology):
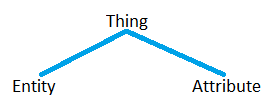
Using the above lexicon, I define each of the terms as follows.
A thing (an instance of Thing), in this lexicon, is one of the following:
· entity (an instance of Entity) … is a Thing that exists in its own right and can be characterized by attribute(s).
· attribute (an instance of Attribute) … is a Thing that is used to characterize an entity.
Note: Distinguishing entities and attributes is the theoretical basis of many database management systems and, especially, relational DBMSs.
I extend our ontology to distinguish various types of Entity and Attribute (because this will greatly aid us in our modeling and implementation work):
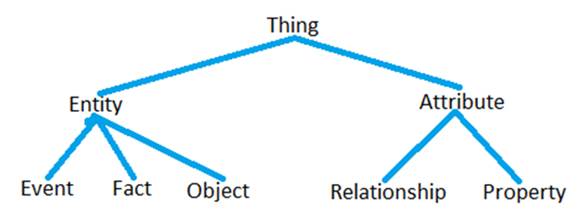
Using the above lexicon, I define each of the terms as follows.
An entity (an instance of Entity), in this lexicon, is one of the following:
· object (an instance of Object) … is a persistent entity, meaning that it exists (and, therefore, is subject to change) across a period of time.
· event (an instance of Event) … is an instantaneous entity, meaning that it occurs at a specific point in time.
· fact (an instance of Fact) … is an entity which is independent of time.
Note that this is a temporal perspective of entities. I adopt it because it is temporality that affects how we store and manage data.
An attribute (an instance of Attribute), in this lexicon, is one of the following:
· relationship (an instance of Relationship) … is an attribute which describes the entity through its relationship to one, or more, other entities.
· property (an instance of Property) … is an attribute which describes the entity directly (with no dependence on other entities).
Note that this is a relational perspective of attributes. I adopt it because relationships and properties are stored and managed differently.
Data models
In the data world, entities are those things that we model first. We then describe those entities with attributes.
A data model, therefore, describes objects, events, and facts with relationships and properties.
Entities
To store data about any instance of an entity, we store the identity of the instance (to distinguish it from other instances of that entity) and any number of additional attributes about the instance. However, the model varies depending on the type of entity.
Being timeless, a Fact is modeled simply (without any time):

Note that there is only one record for each instance. The state of a fact does not change.
Being instantaneous, an Event is modeled with a pertinent point-in-time (here, I assume “date” granularity):

Note that there is only one record for each instance. The state of an event does not change.
Being persistent, an Object is modeled with a pertinent period of time (here, I assume “date” granularity):
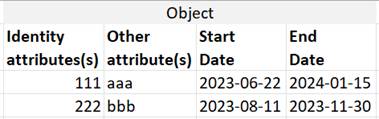
If the state of the Object can change (which is common) and it is desired to record those different states (as is typical in a data warehouse), the “start date” is included in the primary key and multiple records may be recorded for each instance as in the following (where 222 changed state from “bbb1” to “bbb2”):
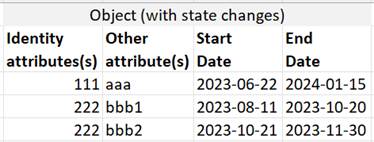
From the above, it’s clear that each type of entity requires a different implementation in the model. Therefore, it is critical to distinguish entities by type when developing your data model.
Attributes
Now consider the following data table that defines 4 employees:
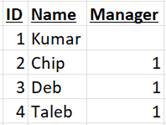
… where:
· “ID” is the identifying attribute.
· “Name” is a property attribute.
· “Manager” is a relationship attribute.
You should notice that:
· The property attribute (Name) is a simple column in which standard values are recorded.
· The relationship attribute (Manager) is a reference column in which the identity of the pertinent manager is recorded.
From the above, it’s clear that each type of attribute requires a different implementation in the model. Therefore, it is critical to distinguish attributes by type when developing your data model.