|
|
Data Modeling
Chip Hartney (The Datamology Company)
First written: February 3, 2024
Some comments about added costs
Abstract
Data modeling is the most critical activity in the implementation of any data solution. I do not exaggerate.
In fact, it is always done. One cannot avoid it. If a data solution is implemented, there is data in some form … and that form has some structure. That structure is referred to as the “model”.
The only question, really, is how much effort is invested in establishing that model. At one end of the effort spectrum is a model that is established by the developer on-the-fly in whatever form s/he desires (without any documentation). At the other end is a model that is systematic, thorough, robust, and even pre-ordained (with substantial documentation).
I believe that data modeling is extremely beneficial and, therefore, worthy of substantial effort.
But just what is data modeling? And how should you think about it? How far should you go?
In this article, I present my perspectives on data modeling with the hope that you’ll be better able to make decisions as to how you will model your data in your organization (or project).
Traditional data modeling
Most practitioners speak of data modeling as a single process that benefits all stakeholders, especially those that develop the solution (developers) and those that use it (users). Because there are multiple stakeholders, there is a need for multiple models related to the same set of data. Practitioners usually advocate the use of a modeling tool that supports the definition and generation of each of those models in an integrated and consistent manner. Some shops manage to accomplish that. But I often find this impractical. Developers and users have very different needs. Also, physical and virtual solutions are implemented (and usually modeled) differently. Most data models, even the best of them, only serve one of those communities and one of those purposes well. (Typically the developer community for physical assets.) I suggest that you may be best-served by focusing on the models that are of the most value and using whichever tools might work best for each particular model. Restating, don’t get hung up on having one data model (or one data modeling tool!) serve all stakeholders.
Traditionally, data modelers (and data modeling tools) suggest the following data models:
· A conceptual data model (CDM) that defines the organization’s business at a high level (from a data point of view) and provides the basis for all other data-based discussions.
· A logical data model (LDM) that adds detail (especially entities and their attributes), again using business-friendly semantics, to give the technical team a basis from which to create and manage the implementation on any data platform.
· A physical data model (PDM) that defines the technical implementation on a given data platform.
I find the conceptual model (and related conceptual modeling effort) to be extremely valuable to all stakeholders in any data project. But the logical and (especially) physical models are useful only to the technical team responsible for developing and maintaining the solution. It is often argued that the logical model is useful to the data users and that’s true to a point. But it is only useful as far as it describes the technical implementation in business-friendly terms. As we’ll see below, the user’s view does not (and should not) align well with the technical implementation. Another problem, at least for RDBMSs (which support both tables and views), is how and where views should be modeled. Some argue views are logical constructs and, therefore, belong in the LDM. But this contradicts the idea that the physical model describes all database constructs. Including views in the PDM, however, places what are frequently the most valuable and important user-facing assets in a model that is overwhelmingly technical and, therefore, confusing.
The most important models
In my experience, following the above traditional guidance proves unsatisfactory (sometimes to the point of being a root cause for failure or abandonment of a project!). Instead, I think we should focus on establishing those models that are most beneficial to the organization.
I think the following models are the most worthy of such effort:
· A conceptual model that describes the organization’s business at a high level (from a data point of view) and provides a basis for all other data-based discussions.
· An implementation model that describes the actual implementation of the data store(s) (tables, views, indexes, etc).
· A usage model that describes the portion of the implementation that is pertinent to a particular set of users (in terms that are appropriate for that community).
In the following, I describe each of the above and show a sample model based on the following scenario:
· The county assessor’s office has a data warehouse that tracks property ownership.
· A group of employees requires the ability to analyze ownership patterns, over time, by ethnicity and city.
Keep in mind that these models, though very different from each other, all describe the above scenario.
Conceptual model
A conceptual model is a high-level model of the business from a data point of view. It identifies the core concepts (people, places, things, events, etc) that the business deals with and the business relationships between those concepts. The language used in this model should be the natural language of the business, itself, and all statements, phrases, and terms should be those that the business uses every day.
If the business cannot agree to such terms, the data solution will fail because it will only ever reflect one set of terms (and understanding).
This model is used by all decision makers with respect to a data project and all parties interested in that project.
Such models might be built with software tools, but even paper diagrams may suffice.
Your technical team may well facilitate the creation (with participation from various business stakeholders) the following conceptual model:
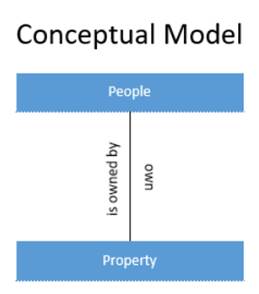
Implementation model
An implementation model is a detailed specification of the data solution for the data platform of choice (such as a particular RDBMS).
This model is used by the technical team to manage the solution through its lifetime.
Such models might be built by hand, but that will be tedious for all but the smallest of solutions. Software tools (typically specialized data modeling tools) are usually employed to ensure accuracy and consistency as well as reducing the burden on the technical staff.
An important decision is just how complete this model is. If your shop intends to manage the RDBMS automatically through the tool, then the model must be complete. Most shops choose a less stringent approach (for a variety of reasons) and use such a tool to supplement their management of the RDBMS. In such cases, the model may not include view definitions, for example. Those may be documented elsewhere and managed through other means.
Your technical team may well develop (without participation or approval from any other stakeholders!) the following implementation model:
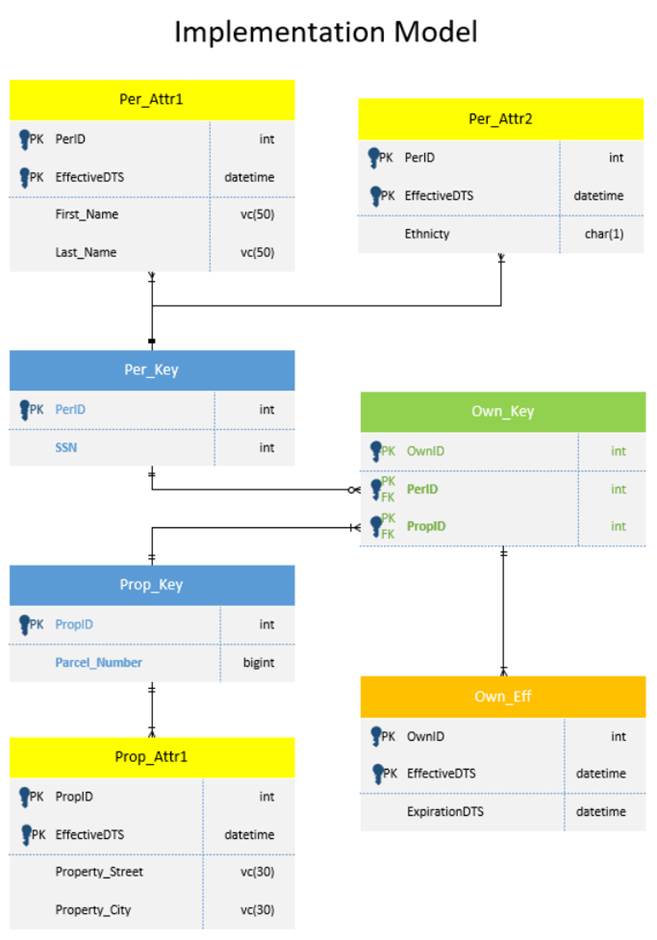
Usage model
A usage model is a user-friendly model that enables them to understand and utilize the modeled solution. In the cases where the users will interact with the assets via SQL (as in an RDBMS), the model necessarily includes the data assets (typically tables and/or views) against which they will write their SQL statements.
Note that the assets will also be defined in the implementation model (for the technical team’s benefit), but the usage model should expose the assets in a form that is most meaningful to the particular users.
This model is used by the target user community to support their day-to-day work.
Such models might be built through a variety of means. Large organizations (with complex data solutions including many data assets) are advised to use data modeling tools to create implementation models and then use automated techniques to extract only the pertinent parts of the implementation model for the particular usage model. Be forewarned, however, that most data modeling tools do not produce quality usage models because they are still tech-centric. You are likely to have to modify even those models that you initially produce through automated means. But this effort is most worthwhile. After all, the investment is only worthwhile if it gets used. And it will only be used if there are helpful aids that make usage simple. Data models (being visual) are especially useful in this regard.
Your technical team may well develop (this time with the user’s participation and approval) the following usage model:
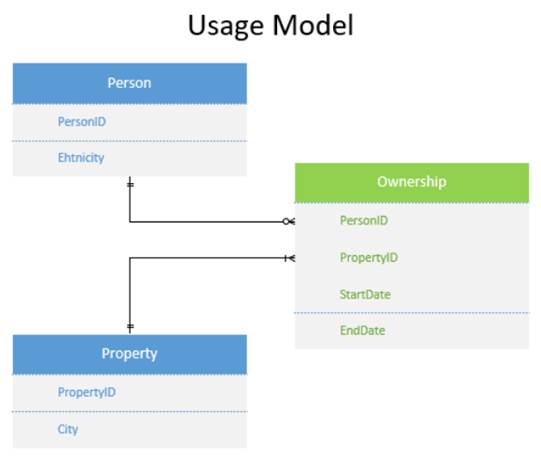
Conclusion
My points in all of this are:
· Stay focused on the models that are most important to your organization.
· Don’t be constrained by the modeling tools.
Data modeling approaches
Overview
Returning to my original point (that every data solution has a data model), it’s more accurate to say that every data solution is of a given architecture. That architecture might be the random structure thrown together by the developer at the time of implementation. This is, in fact, how many architectures are established. I’m thinking here of the simplest of projects … which happen all the time! A technician is asked for a way to store some information by a manager and that technician throws together an Excel workbook with a sheet or two. This kind of “winging it” is reasonably efficient and sufficient. But, I hope you would agree that it is generally better for larger teams or larger projects to follow some best practice in the design of your data stores.
A common misconception is that there is only one way to architect a data model. In fact, there are a number of different architectures used throughout the industry, each with its own costs, benefits, and risks. I do not profess to be experienced enough to thoroughly discuss each. I’m sure there are many I am not even aware of! But I think it appropriate to discuss a few of them here so that some of my other articles will make sense.
But first, a warning. Practitioners (including myself) are often sloppy in their terminology. Below is a list of data modeling … approaches. Some are explicit architectures with specific guidelines as to how to construct each data asset in the solution. In such, the final structure is dictated more than the method used to identify the required assets. Other approaches focus more on the front end, the practice of identifying the necessary assets. This is a broad spectrum … all of which are usually identified as “data modeling” practices. I don’t bother to distinguish them here (leaving that to you). I simply list a number that I am familiar with so as to inform you of the breadth of the data modeling arena.
Common approaches
Here’s the list (with some links to pertinent sources):
• Normal form data modeling (commonly “3NF”)
o Ted Codd
o 1970
•
NIAM (Natural language Information Analysis
Method)
o
G. M. Nijssen
o
Circa 1975
• ER (Entity-Relationship) modeling
o Peter Chen
o 1976
•
Fact-based modeling
o Europe
o
Circa 1978
•
ORM (Object-Role Modeling)
o
Terry Halpin
o
1989
• Dimensional modeling (commonly “star schema”)
o Ralph Kimball
o 1997
o https://www.kimballgroup.com/1997/08/a-dimensional-modeling-manifesto/
•
Data Vault 2.0
o
Dan Lindstedt
o
2000
o
https://datavaultalliance.com/data-vault-2-0-model/
•
FCO-IM (Fully Communication Oriented -
Information Modeling)
o
The Netherlands
o
Circa 2001
•
Anchor modeling
o
Lars Rönnbäck
o
Circa 2006
o
https://www.anchormodeling.com/
• Data Vault (Ensemble)
o Hans Hultgren
o Circa 2011
• COMN (Concept and Object Modeling Notation)
o Ted Hills
o Circa 2017
o
https://technicspub.com/nosql-modeling/
•
USS (Unified Star Schema)
o
Francesco Puppini
o
2020
o
https://technicspub.com/uss/
Caveats:
· Each of the above is only recommended (even by their inventors) for certain uses. There is no one-size-fits-all architecture in data systems.
· I’ve attempted to attribute the above approaches to the appropriate folks and with the appropriate time points. But there is much disagreement on just when/how/who started each approach and whether these are even truly distinct approaches. Suffice it to say that many smart people have tackled data modeling and contributed significant ideas to the field. I apologize to my colleagues if you think I’ve misattributed and misrepresented any of these! (Feel free to ping me with more accurate info and I’ll be happy to update this article.)
My approaches
We data modelers are all opinionated and we evolve our recommendations based on our own experiences. In fact, I think it safe to say that every industry giant noted above, did exactly the same.
I am no different. In my data warehousing practice during the last 10 years, I have come to believe strongly that one of the following architectures should be utilized for the implementation of the core area of an EDW. Note that I recommend them only for EDWs and, specifically, the core of such DWs. (See my article “Functional areas of an EDW” for more on that topic.)
Like most in my profession, I have been greatly informed and influenced by the thoughts of Bill Inmon from my earliest days in the field when he founded Prism Solutions and started formalizing the practice of data warehousing. My thinking about data modeling for EDW cores has evolved, I believe, much like Inmon’s:
· In the 1990s, I advocated the use of ER modeling for EDW cores.
· In the 2000s, I came to appreciate the value of dimensional modeling but concluded that it should be used for the mart area of the EDW, not the core.
· In the 2010s, I came to believe (like Inmon) that data vault modeling was a superior architecture for EDW cores.
However, per my articles “The temporality of data” and “What is an Enterprise Data Warehouse?”, we must utilize the system time temporal features of modern RDBMSs to accurately and effectively manage both system time and business time in an EDW. By 2017, after all of the major vendors had released temporal versions of their RDBMS products, I started becoming dissatisfied with data vault. It’s dependence on LOAD_DTS (the datetime at which each record is loaded into the database) either prevents me from using a temporal database or confuses the solution by presenting system time information in both the temporal columns and the business columns of a data vault. So, with great appreciation, admiration, and thanks for the work done by Dan Lindstedt and Hans Hultgren (and others) in the data vault arena, I suggest the following approaches to data modeling that I believe build on the pillars of data vault and temporality.
Note: I am tempted to call the following approaches “temporal data vault lite” and “temporal data vault” which would, I believe, communicate more accurately the fundamental concepts of these approaches. But I do not wish to step on anyone’s toes nor further complicate the question of whose “data vault” is right. And I definitely do not want to suggest that I am a data vault expert at the level of Lindstedt or Hultgren. So, I use my own names below. Besides, I am not sure it would be appropriate to include “data vault” in these names given my elimination of LOAD_DTS (a fundamental building block of data vault)!
In the following, I use a running example so that the differences will be clear. In these examples, I ignore business time (considering “current state” only) to keep things simple. The reality represented in these examples is as follows:
·
Persons enroll
in classes.
·
Each class is instructed by a person.
·
A class may have a pre-requisite class.
Traditional ER modeling
I included this approach only for comparison’s sake. I did not invent this.
This is a traditional 3NF design.
Example
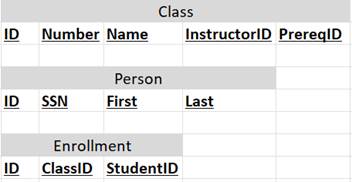
True ER modeling
The first fundamental (and brilliant!) difference between data vault and ER modeling was a return to Chen’s recognition of the difference between, and the equality of, entities and relationships. Over the years ER modeling has generally absorbed 1:1 and 1:n relationships into the entity’s definition (through the use of a foreign key). N:n relationships are still (necessarily) modeled as separate objects, but all other relationships “disappeared” into the entities, themselves. That proved acceptable in transactional databases but few questioned the practice in data warehousing. Data vault models all relationships separately, regardless of cardinality. Cardinality is, therefore, determined by the data (and metadata) as opposed to a database construct (such as a foreign key).
In my approach (using a temporal database!), I adopt this same practice. Entities and relationships are modeled separately!
Doing so would not make much sense in a transactional
database but, in data warehousing, this provides a number of tremendous
benefits.
Example
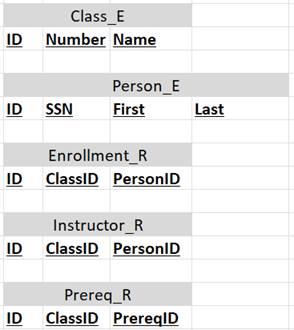
Benefits
As compared to traditional ER model:
·
Easier to interpret:
o
Natural data model (matches business reality and
is, therefore, easier to interpret).
o
Clearer column names (for 1:n
FKs) because, in stand-alone table, both purpose and referenced table are made
clear.
·
Simpler development and maintenance:
o
Fewer (and simpler!) table structures.
o
Fewer ETL patterns (and more standardized to
boot).
o
Handles relationship cardinality changes without
refactoring any table.
o
Relationships can be added without refactoring
any existing table/ETL.
o
Relationships can be terminated simply by
terminating its ETL (no refactoring).
·
More efficient ETL:
o
All entity tables can be loaded in parallel.
o
All relationship tables can be loaded in
parallel.
o
Supports INSERT-only loading paradigm.
·
More capable model:
o
Supports attributes of 1:1 and 1:n relationships.
Costs
As compared to traditional ER model:
·
More tables and, as a consequence, the
following:
o More objects to maintain.
o
More JOINs required in queries.
o
Possibly worse query performance (depending on
RDBMS and platform).
·
Less familiar to IT.
Ensemble ER modeling
The second fundamental (and brilliant!) difference
between data vault and ER modeling was the introduction of decomposition. Instead of an object being defined by a
single table, it would now be decomposed into an ensemble of related tables. Keys are only recorded once (in their own
table). Attributes can be divided among number of tables.
Again, the basic recognition is that one need not compose a single table
that includes every possible attribute.
In my approach (again, using a temporal database!), I adopt this same practice. Entities and relationships are defined by an ensemble of related tables.
Again, doing so would not make much sense in a transactional database. But, in data warehousing, this provides a number of tremendous benefits.
Example
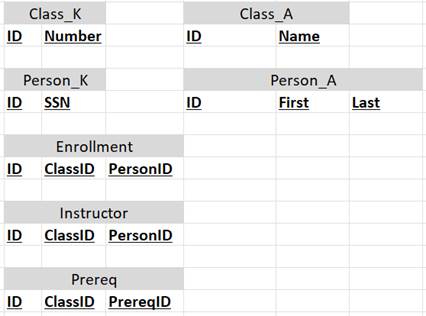
Benefits
As compared to true ER model:
·
All benefits of true ER model.
·
Simpler development and maintenance:
o
Still fewer (and simpler!) table structures.
o
Still fewer ETL patterns (and more standardized
to boot).
o
Attributes can be added (to entities or
relationships) without refactoring any existing table/ETL.
o
Attributes can be segregated in any useful way
(different sources; different cadences; different audiences; different
security; etc)
o
Business time can be added selectively (only to
the attributes that change).
·
Further benefits if business time is added
(which is extremely likely):
o
Business keys (and, therefore, key mappings) are
recorded only once.
o
Business time segregated from keys (eliminating
redundancy and confusion).
o
By applying business time only to the attributes
that require it, substantial storage can be saved.
Costs
As compared to true ER model:
·
More tables and, as a consequence, the
following:
o
More objects to maintain.
o
More JOINs required in queries.
o
Possibly worse query performance (depending on
RDBMS and platform).
Some comments about added costs
Regarding the “costs” noted above …
I do not generally consider these “costs” to be problematic. I list them above because they are always mentioned in workshops that introduce data vault concepts. So they need to be addressed. Here are my thoughts.
Since when is familiarity a driving reason to choose one technology solution over another? I’ve been in IT for a long time and can personally attest to the rapid (and increasing) rate of change in the field. To be successful, we must continually learn and adapt. If familiarity were a valid measure of technology solutions, we would still be storing data in network databases on mainframes that are populated by JCL jobs written in Assembler.
As for the number of tables increasing. True enough. But I maintain the following:
·
There are more tables, but maintenance of those tables
is reduced as we minimize the types of distinct tables and processes that
populate and manage them. The savings in
this regard may outweigh the cost related to increased quantity.
·
There are more JOINs, but only in the views that
expose the data to the users. (I
strongly advocate that all such access be done through views.) Therefore, it is
only the technical staff that is faced with “more JOINs”, but these are
technically savvy folks that are quite capable of writing JOINs. And they only need to do it once … when
defining the view.
· Performance
will not necessarily be worse. The
tables will be more compact, with more records per block and page of storage,
which makes the query engine more performant.
I agree that performance will generally be worse if you need to recompose
the entire asset (all attributes and relationships). But that is very rarely the case. Case studies show that most queries in a data
warehouse use only a few of the attributes available for any given entity. If only a few are needed, performance may very
well be better!